If you want to try out the stuff described in this post, check out this this repo.
Did you know that Ninja Turtles, X-Men and effective tests have something in common?
Tests are good if they catch errors 🔗
The purpose of testing software is to ensure its quality. The idea is simple: catch errors before the user does. While the idea is simple the practice is not. Writing tests is not straightforward, and writing good tests is even harder. Much has been written about the topic, e.g., Testing Without Mocks and Why Good Developers Write Bad Unit Tests.
Nevertheless, this means that not only is the quality of software variable but so is the quality of tests. Moreover, errors are expensive, and the later you discover them in the software development cycle the more expensive they get. Consequently, we have a financial incentive to ensure the quality of our tests. How can we do that?
When talking about gauging test quality, it is common to stumble upon code coverage. A metric is defined as the share of lines of the total codebase that were executed during a test suite run. To understand if that is a good metric, let us ponder the following questions:
- If I have 100% coverage, have I tested 100% of the functionality?
- Is 100% code coverage better than 80%?
- Or, are my tests any good?
The answer to all those questions is: it depends. Annoying, I know. The thing is, code coverage is a blunt metric because executing a line does not necessarily mean all behaviors encapsulated in that line were tested.
To explain this, let us look at an example of a simple calculator.
export class Calculator {
add(a: number, b: number): number {
return a + b;
}
multiply(a: number, b: number): number {
return a * b;
}
isPositive(number: number): boolean {
return number >= 0;
}
}
This is a silly calculator able to do basic addition, and multiplication and to check if a number is positive. Despite its silliness, I take pride in producing high-quality code, so I have created the following unit test suite to go with it.
import { Calculator } from "./calculator";
describe("Calculator", () => {
let calculator: Calculator;
beforeEach(() => {
calculator = new Calculator();
});
test("add should return the sum of two numbers", () => {
expect(calculator.add(5, 2)).toBe(7);
});
test("multiply should return the product of two numbers", () => {
expect(calculator.multiply(3, 4)).toBe(12);
});
test("isPositive should return true if the number is positive", () => {
expect(calculator.isPositive(5)).toBe(true);
});
test("isPositive should return false if the number is negative", () => {
expect(calculator.isPositive(-3)).toBe(false);
});
});
Executing these tests yields a perfect 100% coverage and all tests pass with flying colors. Awesome, let us ship it. The calculator hits production and boom, we have an incident. It turns out the calculator has a bug (did you spot it?). The method isPositive returns true for zero, when the correct response should be false.
Alright, the example is stupid but the point I am trying to make is not. Code coverage is not a reliable metric if you want to be confident that your tests can catch errors. 80% code coverage of good tests can be better than 100% coverage of bad tests.
We need to find a different way.
How can we check if our tests are good? 🔗
What we are talking about here is to find a reliable method to test our tests. A possible approach to achieve that is to leverage something called mutation testing. It is a type of testing where errors are deliberately introduced in the source code to see if your test suite will detect them. These modified variants of the source code with injected errors are called mutants, and we want to kill them.
Mutation testing offers a way 🔗
Mutation testing is all about killing mutants. On a high level, the process is:
- Create mutants by modifying the source code to introduce errors.
- Execute your existing test suite against the mutants.
- If the tests fail, the mutant is killed. If the tests pass, the mutant survives.
- If mutants survive, improve the tests and repeat the process.
Or as a visual representation:
---
title: The process of mutation testing
---
flowchart LR
sourceCode[Source Code] -->|Modified by| mutator(Mutator)
mutator -->|Creates| mutants[[Mutants]]
mutants -->|Validated by| tests(Test Suite)
tests --> check{Is alive?}
check -->|No| dead["🥳 Nailed it"]
check -->|Yes| alive["😭 Fix the test"]
Figure 1. A high-level process of how mutation testing works.
The kind of modifications done to the source are not random but based on pre-defined rules, called mutators or operators. There are many types of mutations, and different mutation testing frameworks will support different mutators (I am using Stryker for these examples and here is the full list of mutators supported by them). A few common types are:
- Statement mutations change statements, e.g., duplicating or deleting a statement or a block of statements.
- Decision mutations alter operators, e.g., arithmetical, relational, and logical operators.
- Value mutations transform constants or literals in the code, e.g., changing a value to a very big or small value.
- Exception Mutations modify exception handling in the code, e.g., removing a try-catch block.
- Function Call Mutations mutate the parameters of a function call, or remove the function call entirely.
Enough theory, now we have a rough understanding of how mutation testing works, let us apply this to our calculator.
A high mutation score indicates high test quality 🔗
If we run the mutation tests on our calculator and its test suite, we get an output like this:
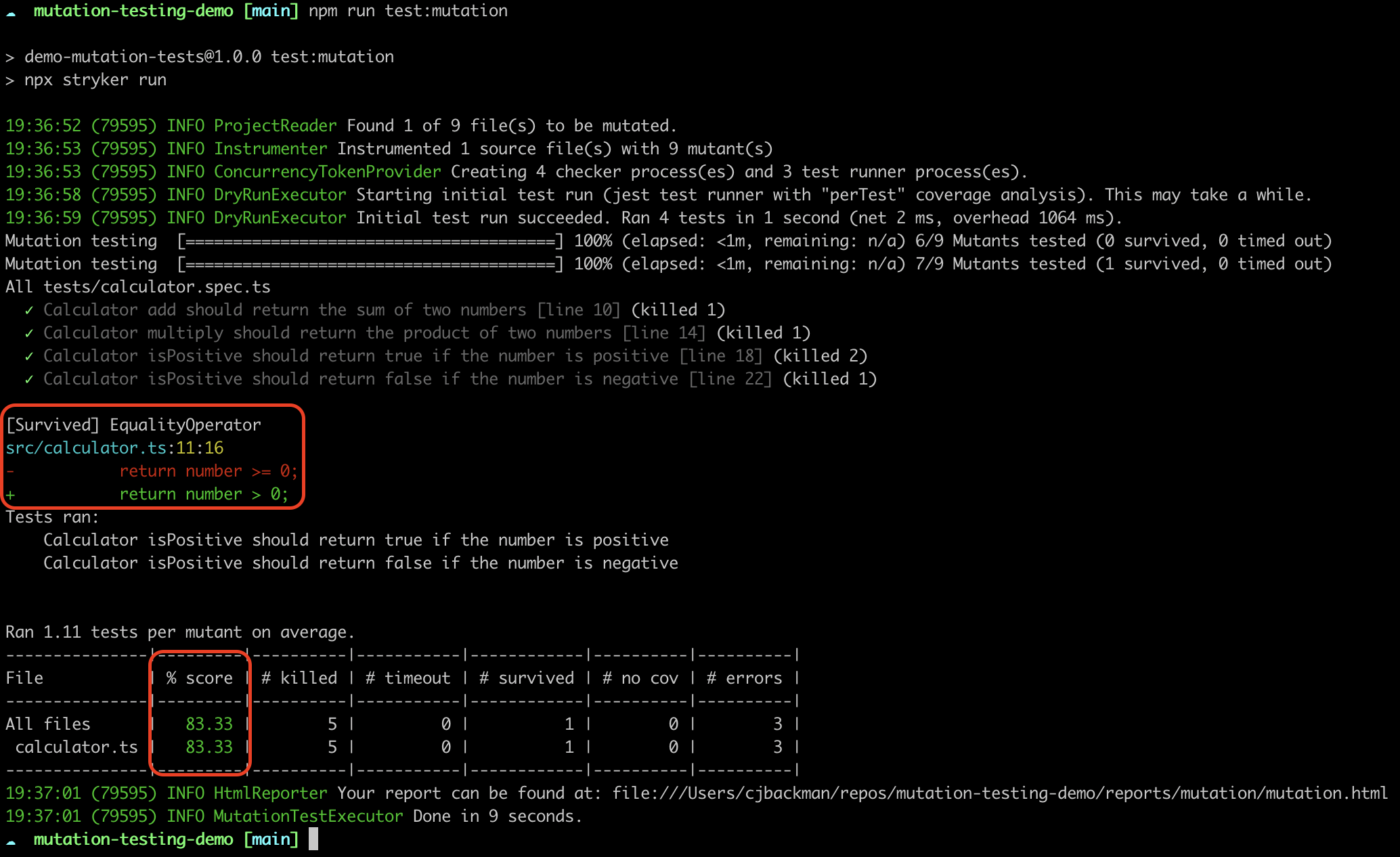
Figure 2. The output from Stryker when mutation testing the calculator.
Do not mind all the information but you will see that we get something that says % score (highlighted by a red box), which is the mutation score. This represents the share of successfully killed mutants. 100% means all mutants were killed (good tests!) and 0% percent means all mutants survived (bad tests!). Additionally, you can see information about the surviving mutant (also highlighted by a red box), namely applying the EqualityOperator so that return number >= 0; was changed to return number > 0;.
How can we improve our tests based on this information? We add a test for the case .isPositive(0) like:
test("isPositive should return false if the number is zero", () => {
expect(calculator.isPositive(0)).toBe(false);
});
If re-run our unit tests, including this new case, we catch the bug. After fixing the bug and re-running the mutation tests we get a code coverage and mutation score of 100%. With this simple example, we see that mutation testing allows us to:
- Measure the effectiveness of our tests at a granular level.
- Provide insights about gaps in our test suite and how to improve it.
- Indirectly contribute to better code quality by making tests more comprehensive.
However, as always, there is a different side of the coin and we will explore that next.
Do not aim for a 100% mutation score 🔗
First off, do not aim for a 100% mutation score. It is rarely feasible in a large codebase because chances are you will encounter some equivalent mutants. Those mutations are syntactically different from the original program, but functionally identical, thus leading to false positives. In a large codebase, these mutations can be difficult to locate and remove. Accepting a score lower than 100% might be a more pragmatic solution.
Another misleading outcome can come from incompetent mutants. Those are mutations that result in code that is so faulty it will always be killed. This happens when the mutant, e.g., causes the program to crash, goes into an infinite loop or always throws an exception. The mutations will be killed not because the tests are good, but because the mutant was doomed from the start.
Finally, mutation testing tends to be time-consuming and computationally expensive due to the large number of mutants. Also, there is an added complexity of having to juggle yet another framework, which might not be justified for a smaller project.
Treat yourself to the occasional mutation test 🔗
That is it, let us sum up the tradeoffs of mutation testing.
| Mutation tests yay | Mutation tests nay |
|---|---|
| Measures test effectiveness | Computationally expensive |
| Provides insights about test improvements | Can be misleading |
| Contributes to higher code quality | Adds complexity |
And now you know what Ninja Turtles, X-Men and effective tests have in common? Mutants. They probably will not save the world, but they might save you from shipping that next bug into production.
Glossary 🔗
PS. I like glossaries, so I asked ChatCPT to generate one based on this article.
| Term | Description | Example |
|---|---|---|
| Code Coverage | The percentage of code executed during testing. It measures how much of the codebase is tested by the test suite. | Achieving 100% code coverage implies every line of code was executed during tests. |
| Mutation Testing | A method where errors are intentionally introduced into the source code to test if existing tests can detect them. | Injecting a fault in a calculator’s addition function to see if tests detect the error. |
| Mutants | Modified versions of the original code created in mutation testing, each containing a specific, deliberate error. | An altered line of code in a method, such as changing a >= operator to > in a conditional statement. |
| Mutators/Operators | Specific rules or methods used in mutation testing to introduce errors. | Changing an arithmetic operator or modifying the return value of a function. |
| Statement Mutations | A type of mutation where statements are altered, like duplicating, deleting, or changing the sequence of statements. | Removing a crucial line of code that checks user input validity. |
| Decision Mutations | Mutations that involve changing decision-making constructs in the code, such as conditional statements. | Reversing a condition in an if statement from if (x > 0) to if (x < 0). |
| Value Mutations | Mutations where constants or literals are changed to different values. | Changing a default setting value from 10 to -10. |
| Exception Mutations | Involves modifying exception handling aspects of the code, like altering or removing try-catch blocks. | Eliminating a try-catch block that handles file reading errors. |
| Function Call Mutations | Mutations that change the behavior of function calls, either by altering parameters or omitting the call. | Modifying the parameters of a function call or removing a function call entirely from a code block. |
| Mutation Score | A metric in mutation testing that indicates the percentage of mutants successfully detected and ‘killed’ by the tests. | A mutation score of 80% indicates that 80% of the introduced mutants were detected by the tests. |
| Equivalent Mutants | Mutants that, despite being syntactically different from the original code, do not alter the program’s external behavior. | Changing a loop condition in a way that does not affect the loop’s number of iterations or its outcome. |
| Incompetent Mutants | Mutants that are so flawed they are always detected by tests, not necessarily indicating good test quality. | A mutant causing a syntax error or a logical contradiction, leading to immediate detection. |